40기 면접질문
- FORIGN KEY
: 데이터의 중복성을 배제하기 위해 정규화 작업을 통해 하나의 테이블을 여러 개의 테이블로 나누는데 쪼개어진 테이블중 필요한 데이터를 가져올 수 있도록 부모테이블의 PK를 자식테이블의 FK로 두고 관계형성을 맺는다.
[p241]
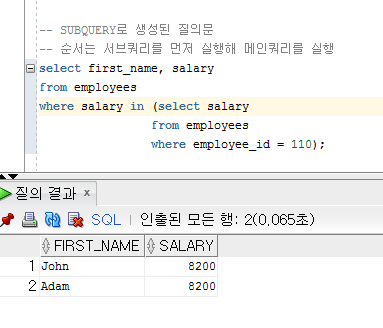
▶ 서브쿼리
: DML 명령문 그 중 SELECT문을 섞어서 사용하는 쿼리
: 어떤 상황이나 조건에 따라 변할 수 있는 데이터 값을 비교하거나 근거로 하기 위해 SQL문 안에 작성하는 작은 SELECT문을 의미한다.
: SQL문을 실행하는데 필요한 데이터를 추가로 조회하기 위해 SQL문 내부에서 사용하는 SELECT문을 의미한다.
: 실행순서는 서브쿼리를 먼저 실행한 후 메인쿼리를 실행한다.
서브쿼리를 사용하지 않는다고 하면 두번을 조회해야겠지만 서브쿼리를 이용한다면 두 개를 합친 결과를 얻을 수 있다.
두 개로 나눠 사용한다면 오류가 두번 발생할 수 있다.
▶ 서브쿼리의 특징 p244
1. 서브쿼리는 연산자와 같은 비교 또는 조회 대상의 오른쪽에 놓이며 괄호( )로 묶어서 사용한다.
2. 특수한 몇몇 경우를 제외한 대부분의 서브쿼리에서는 ORDER BY절을 사용할 수 없다.
3. 서브쿼리의 SELECT절에 명시한 열은 메인쿼리의 비교 대상과 같은 자료형과 같은 개수로 지정해야 한다. 즉 메인쿼리의 비교 대상 데이터가 하나라면 서브쿼리의 SELECT절 역시 같은 자료형인 열을 하나 지정해야 한다.
4. 서브쿼리에 있는 SELECT문의 결과 행 수는 함께 사용하는 메인쿼리의 연산자 종류와 호환 가능해야 한다. 예를 들자면, 메인쿼리에 사용한 연산자가 단 하나의 데이터로만 연산이 가능한 연산자라면 서브쿼리의 결과 행 수는 반드시 하나여야 합니다.
[SUBQUERY로 생성된 질의문]
: 순서는 서브쿼리를 먼저 실행해 메인쿼리를 실행
①단일행 서브쿼리 : 실행결과가 하나인 단일행 서브쿼리
단일행 연산자 : >, >=, =, <=, <, !=

>, < 크다, 작다로는 원하는 값이 나오지 않는다.

② 다중행 서브쿼리 : 실행결과가 여러 개인 다중행 서브쿼리
| 다중행 연산자 | 설명 |
| IN | 메인쿼리의 데이터가 서브쿼리의 결과 중 하나라도 일치한 데이터가 있다면 TRUE |
| ANY, SOME | 메인쿼리의 조건식을 만족하는 서브쿼리의 결과가 하나 이상이면 TURE |
| ALL | 메인쿼리의 조건식을 서브쿼리의 결과 모두가 만족하면 TRUE |
| EXISTS | 서브쿼리의 결과가 존재하면(즉, 행이 1개 이상일 경우) TRUE |
다중행 연산자 in을 사용해 원하는 데이터 찾기
in은 연산자 중에서 가장 자주 사용하는 연산자이다.
[Sarah의 입사년도보다 먼저 들어온 사람을 찾기]
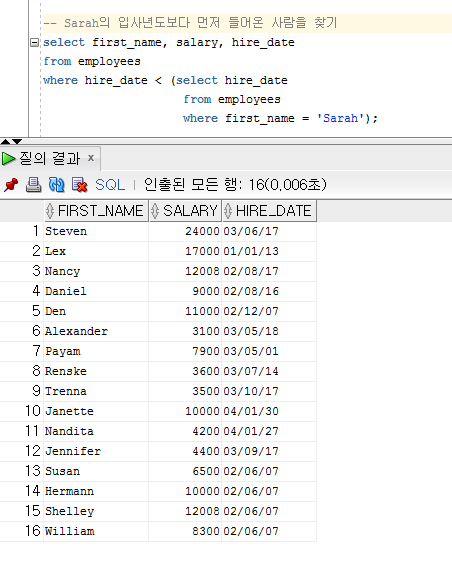
select first_name, salary, hire_date
from employees
where hire_date < (select hire_date
from employees
where first_name = 'Sarah');
[Last name이 'Seo'인 사람과 같은 부서에서 일하는 사람들의 사원번호, 이름, 부서번호를 출력하시오.]
메인쿼리가 아닌 서브쿼리일 경우, 괄호 ( ) 안에 들어가야 한다는 것 잊지말기!

rownum
:실제로 존재하지 않는 컬럼명, 동적으로 하나의 row가 질의될 때마다 붙이는 번호를 붙여주는 컬럼. 항상 1부터 시작한다. rownum을 사용자에게 게시글을 2가 빠지지 않게 보여주기 위해 존재한다.

pseudo column : 의사컬럼
[다시 해보는 중]


아.. 이렇게 따로 하면 오류 발생할 가능성이 높으니까 나누는 거구낭,, 캡쳐해놓은 거 보고 다시 확인하기
[서브쿼리, 함수와 함께 사용하기]
[연습] 평균급여보다 많이 받는 사람들의 명단(사원번호, 이름, 급여를 출력)
- 평균급여를 질의하는 sql
- 사원번호, 이름, 급여를 출력 시 필요한 sql 필요

select employee_id, first_name, salary
from employees
where salary > (select avg(salary)
from employees);
▶ 다중행 서브쿼리: 실행결과가 여러 개인 다중행 서브쿼리
단일행 서브쿼리보다 다중행 서브쿼리를 더 많이 사용하는 편이다.
하나의 컬럼의 여러개의 데이터
부서별 급여가 가장 큰 데이터를 출력하세요.
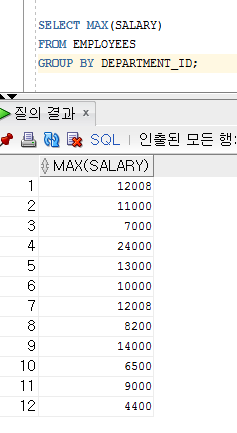

[다중행 연산자 P250]
▶ IN 연산자
: ANY, SOME 메인쿼리의 조건식을 만족하는 서브쿼리의 결과가 하나 이상 TRUE라면 메인쿼리 조건식을 TRUE로 반환해 주는 연산자, ANY는 보통 비교연산자와 사용한다. (<ANY, >ANY, >=ANY, <=ANY, !=ANY) (IN연산자와 동일)
: ALL
: EXIST
예)

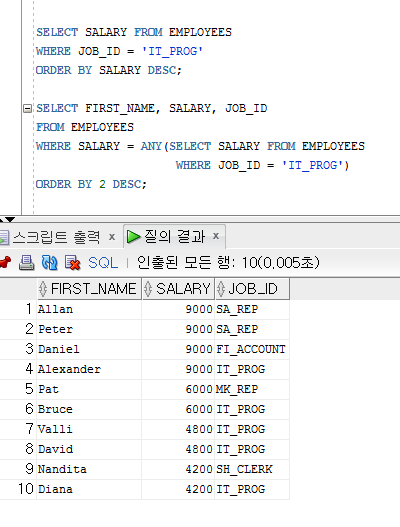
▶ ANY 연산자
[< ANY]
(위의 데이터를 참고, 'IT_PROG' 9000, 6000, 4800, 4800, 4200)
직책이 'IT_PROG'보다 급여가 적은 사람을 (어느 것이라도) 출력해라.

[> ANY]
'IT_PROG' 9000, 6000, 4800, 4800, 4200보다 급여를 많이 받는 사람이 출력된다.

[= ANY]
'IT_PROG' 9000, 6000, 4800, 4800, 4200와 급여가 같은 데이터를 출력한다.
▶ ALL 연산자
: ANY 및 SOME과 달리 ALL 연산자는 서브쿼리의 모든 결과가 조건식에 맞아떨어져야만 메인쿼리의 조건식이 TRUE가 되는 연산자이다.
[> ALL]
'IT_PROG'에서 가장 많은 급여인 9000보다 큰 값이 출력된다.
모든 것보다 큰 것?

[< ALL]
'IT_PROG'에서 가장 적은 급여인 4200보다 적은 값이 출력된다.
가장 큰 값보다 작은 것?

ANY, ALL 중요
▶ EXISTS 연산자
: 서브쿼리에 결과 값이 하나 이상 존재하면 조건식이 모두 TRUE, 존재하지 않으면 FALSE가 되는 연산자이다.
기본 예제
부서번호가 30인 직원을 출력하는 쿼리이다.

데이터가 존재하느냐 물어보는 연산자 EXISTS

select department_id, department_name
from departments
where exists(select * from employees
where department_id = 30);
[연습문제] 조인으로 할지 서브쿼리로 할지 고민해서 풀기
<내가 푼 거>랑 선생님이 주신 정답이랑 비교해보기

1) 업무의 종류가 CLERK인 사람들중에서 근속년수가 12년인 직원들에게 상여금 10%를 지급하는 쿼리문을 작성하세요. (이름, 입사일, 근속년수, 부서명, 업무명, 급여, 특별상여)

select e.first_name 이름, e.hire_date 입사일, substr(sysdate, 1,2)- substr(e.hire_date,1,2) 근속년수, d.department_name 부서명, j.job_title 직책, e.salary 급여, e.salary*1.1 특별상여
from employees e, departments d, jobs j
where
e.job_id like '%CLERK%' and
e.job_id = j.job_id and
e.department_id = d.department_id and
substr(sysdate,1,2)-substr(e.hire_date,1,2) >= 12;
2) 업무의 종류가 CLERK인 사람들중에서 근속년수가 12년 이상인 직원의 이름, 입사일, 근속년수, 부서명, 업무명, 급여 조회, to_number를 사용해도 되지만 안해도 된다.

select e.first_name 이름, e.hire_date 입사일, substr(sysdate,1,2)-substr(e.hire_date,1,2) 근속년수, d.department_name 부서명, j.job_title 직책, e.salary 급여
from employees e, jobs j, departments d
where
e.job_id like '%CLERK%' and
e.job_id = j.job_id and
e.department_id = d.department_id and
substr(sysdate,1,2)-substr(e.hire_date,1,2) >= 12;
3) 사원번호, 근무기간, 업무명을 조회
예) Smith는 5년 근무한 IT_PROG이다.

select e.first_name ||'은 '|| trunc((js.end_date- js.start_date)/365)||'년 '||
trunc(((js.end_date- js.start_date)/365 -trunc((js.end_date- js.start_date)/365))*10) || '개월 근무한 '
||js.job_id||'이다.'
from
employees e, job_history js, departments d
where
e.employee_id = js.employee_id
and
js.department_id = d.department_id;
4) 'Adam'보다 일찍 입사한 사람들의 명단(이름, 입사일) 조회

<내가 풀어본 것>
select first_name, hire_date
from employees
where hire_date < (select hire_date
from employees
where hire_date < 'Adam');
→ where hire_date < 'Adam'가 아니라 where first_name = 'Adam'이 와야 한다.
select first_name, hire_date
from employees
where hire_date < (select hire_date
from employees
where first_name = 'Adam');
5) 평균급여를 초과하는 급여를 받는 사람의 이름, 급여, 부서명(부서아이디가 아님) 조회
조인을 할 때는 where절을 사용하고 추가 조건들 또한 where절 안에 넣는다.

select
e.first_name, e.salary, d.department_name
from
employees e, departments d
where
e.department_id = d.department_id
and
e.salary > (select avg(salary) from employees);
'개발자로 가는 길(국비지원과정) > 2. Oracle' 카테고리의 다른 글
| [210528금] Mybatis 오라클, 자바 연동 + <다른 분반 A반 필기 내용 참고> (0) | 2021.05.28 |
|---|---|
| [210527목] 오라클 자체조인 복습, 자바와 오라클 연동하기 (0) | 2021.05.27 |
| [210525화] 오라클 조인(등가/외부/셀프) (0) | 2021.05.25 |
| [210524월] 단일함수, 그룹함수(group by, having) (0) | 2021.05.23 |
| 9주차 질문 (0) | 2021.05.23 |



